mirror of
https://github.com/UglyToad/PdfPig.git
synced 2026-03-10 00:23:29 +08:00
update the github pages site
updates the information on the github pages site for the new api changes. includes some more seo friendly terms to improve discoverability, more engaging images as well as comprehensive code examples to improve onboarding.
This commit is contained in:
BIN
docs/builder-output.png
Normal file
BIN
docs/builder-output.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 32 KiB |
276
docs/index.md
276
docs/index.md
@@ -1,88 +1,202 @@
|
||||
<image src="https://raw.githubusercontent.com/UglyToad/Pdf/master/documentation/pdfpig.png" width="128px" height="128px"/>
|
||||
|
||||
[PdfPig](https://github.com/UglyToad/PdfPig) is a fully open-source .NET standard compatible library that enables users to extract text content from PDFs in C#.
|
||||
[PdfPig](https://github.com/UglyToad/PdfPig) is a fully open-source Apache 2.0 licensed and .NET Standard compatible library that enables users to read and create PDFs in C#, F# and other .NET languages. It supports all versions of .NET back to .NET 4.5.
|
||||
|
||||
Using PdfPig users can read text from a PDF in C# without the need for commercial libraries.
|
||||
## Installation ##
|
||||
|
||||
The package is available via the releases tab or from Nuget:
|
||||
|
||||
[https://www.nuget.org/packages/PdfPig/](https://www.nuget.org/packages/PdfPig/)
|
||||
|
||||
Or from the package manager command line:
|
||||
|
||||
> Install-Package PdfPig
|
||||
|
||||
## Features ##
|
||||
|
||||
+ Extracts the position and size of letters from any PDF document. This enables access to the text and words in a PDF document.
|
||||
+ Allows the user to retrieve images from the PDF document.
|
||||
+ Allows the user to read PDF annotations, PDF forms, embedded documents and hyperlinks from a PDF.
|
||||
+ Provides access to metadata in the document.
|
||||
+ Exposes the internal structure of the PDF document.
|
||||
+ Creates PDF documents containing text and path operations.
|
||||
+ Read content from encrypted files by providing the password.
|
||||
|
||||
This provides an alternative to the commercial libraries such as [SpirePDF](https://www.e-iceblue.com/Introduce/pdf-for-net-introduce.html) or copyleft alternatives such as [iText 7](https://github.com/itext/itext7-dotnet) (AGPL) for some use-cases.
|
||||
|
||||
It should be noted the library does not support use-cases such as converting HTML to PDF or from other document formats to PDF. For HTML to PDF a good quality solution is [wkhtmltopdf](https://wkhtmltopdf.org/). It also does not currently support generating images from PDF pages. If you need this functionality see if [docnet](https://github.com/GowenGit/docnet) meets your requirements.
|
||||
|
||||
## Getting Started ##
|
||||
|
||||
The Portable Document Format (PDF) is a document format which is focused on presentation. This means as far as possible PDFs will appear the same on most devices. For this reason PDFs tend to lose semantic meaning for their content including ordering of text, separation of text sections, etc.
|
||||
|
||||
PdfPig provides access to the letters on each page in a PDF. This can be used to rebuild text from a PDF in C# (or other .NET languages).
|
||||
|
||||
To open a PDF document and read the letters, words and images:
|
||||
|
||||
using System.Collections.Generic;
|
||||
using System.Linq;
|
||||
using UglyToad.PdfPig;
|
||||
using UglyToad.PdfPig.Content;
|
||||
|
||||
public static class Program
|
||||
{
|
||||
public static void Main()
|
||||
{
|
||||
using (PdfDocument document = PdfDocument.Open(@"C:\path\to\pdffile\file.pdf"))
|
||||
{
|
||||
foreach (Page page in document.GetPages())
|
||||
{
|
||||
IReadOnlyList<Letter> letters = page.Letters;
|
||||
string example = string.Join(string.Empty, letters.Select(x => x.Value));
|
||||
|
||||
IEnumerable<Word> words = page.GetWords();
|
||||
|
||||
IEnumerable<IPdfImage> images = page.GetImages();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
For password protected PDF documents you can provide a set of passwords using the parsing options class:
|
||||
|
||||
ParsingOptions parsingOptions = new ParsingOptions
|
||||
{
|
||||
Passwords = new List<string> {"a password", "password123"}
|
||||
};
|
||||
|
||||
using (PdfDocument document = PdfDocument.Open(@"C:\path\to\pdffile\file.pdf", parsingOptions))
|
||||
{
|
||||
// Get the title from the document metadata.
|
||||
Console.WriteLine(document.Information.Title);
|
||||
|
||||
foreach (Page page in document.GetPages())
|
||||
{
|
||||
IReadOnlyList<Letter> letters = page.Letters;
|
||||
Console.WriteLine(letters.Count);
|
||||
}
|
||||
}
|
||||
|
||||
This also shows accessing document metadata using the `document.Information` property. All metadata is optional according to the specification so all entries can be `null`.
|
||||
|
||||
Letters can be used by consumers to build text and content extraction capabilities into their software. For example table detection. There are many properties for letters in PDFs. See the [wiki page](https://github.com/UglyToad/PdfPig/wiki/Letters) for full details of the `Letter` API.
|
||||
|
||||
The image below shows an example of the letter (teal) and word (pink) bounding boxes (`GlyphRectangle` for letter):
|
||||
|
||||

|
||||
|
||||
## Creating Documents ##
|
||||
|
||||
PdfPig can be used to make a PDF document in C# and other .NET languages. At the moment the API supports drawing letters and paths. The code snippet shows creating a new PDF document with 1 A4 page and writing some text on that page in Helvetica before saving the file to `C:\temp\file.pdf`:
|
||||
|
||||
using System.IO;
|
||||
using UglyToad.PdfPig.Content;
|
||||
using UglyToad.PdfPig.Core;
|
||||
using UglyToad.PdfPig.Fonts.Standard14Fonts;
|
||||
using UglyToad.PdfPig.Writer;
|
||||
|
||||
public static class Program
|
||||
{
|
||||
public static void Main()
|
||||
{
|
||||
PdfDocumentBuilder builder = new PdfDocumentBuilder();
|
||||
|
||||
PdfDocumentBuilder.AddedFont helvetica = builder.AddStandard14Font(Standard14Font.Helvetica);
|
||||
PdfDocumentBuilder.AddedFont helveticaBold = builder.AddStandard14Font(Standard14Font.HelveticaBold);
|
||||
|
||||
PdfPageBuilder page = builder.AddPage(PageSize.A4);
|
||||
|
||||
PdfPoint closeToTop = new PdfPoint(15, page.PageSize.Top - 25);
|
||||
|
||||
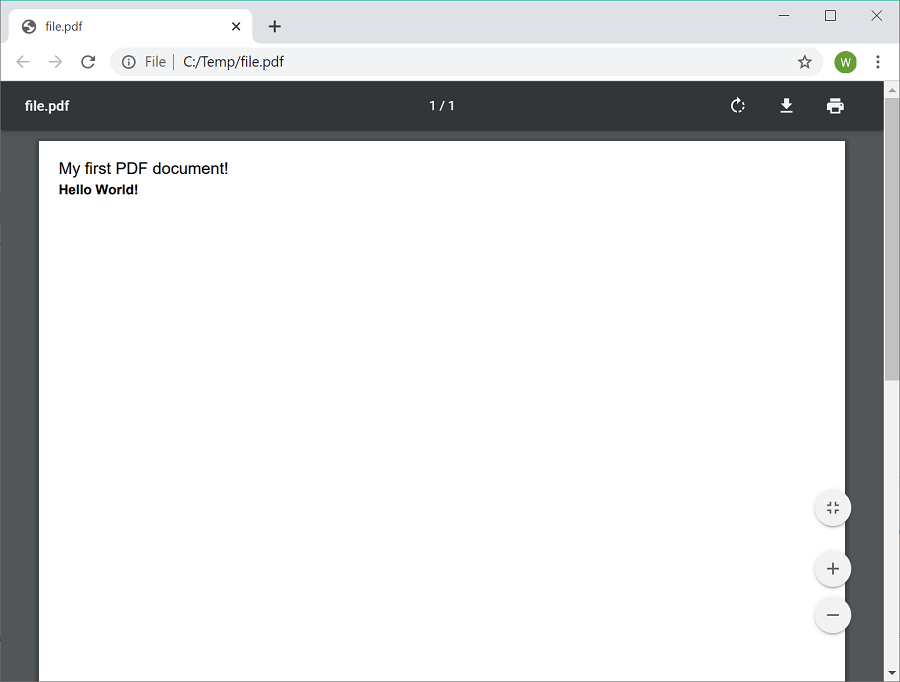
page.AddText("My first PDF document!", 12, closeToTop, helvetica);
|
||||
|
||||
page.AddText("Hello World!", 10, closeToTop.Translate(0, -15), helveticaBold);
|
||||
|
||||
File.WriteAllBytes(@"C:\temp\file.pdf", builder.Build());
|
||||
}
|
||||
}
|
||||
|
||||
The output is a file with the text "My first PDF document!" and then "Hello World!". Since PDF coordinates run from the bottom of the page upwards the Y coordinate of the top of the page is higher than 0 and the bottom of the page has a Y value of 0. The output file is shown below in Chrome's PDF viewer:
|
||||
|
||||
|
||||
|
||||
You can also use TrueType fonts which support non-ASCII text by registering the font with the `PdfDocumentBuilder` prior to use:
|
||||
|
||||
PdfDocumentBuilder builder = new PdfDocumentBuilder();
|
||||
|
||||
// You must provide a valid path to a .ttf file.
|
||||
byte[] robotoBytes = File.ReadAllBytes(@"C:\fonts\roboto.ttf");
|
||||
PdfDocumentBuilder.AddedFont roboto = builder.AddTrueTypeFont(robotoBytes);
|
||||
|
||||
See the [document creation](https://github.com/UglyToad/PdfPig/wiki/Document-Creation) page on the wiki for more details.
|
||||
|
||||
## PdfDocument ##
|
||||
|
||||
The `PdfDocument` provides access to XMP format metadata, AcroForms, Embedded files used by file annotations, bookmarks indicating the internal structure of the document and much more. Some examples are shown in the code sample:
|
||||
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.Xml.Linq;
|
||||
using UglyToad.PdfPig;
|
||||
using UglyToad.PdfPig.AcroForms;
|
||||
using UglyToad.PdfPig.AcroForms.Fields;
|
||||
using UglyToad.PdfPig.Content;
|
||||
using UglyToad.PdfPig.Outline;
|
||||
|
||||
public static class Program
|
||||
{
|
||||
public static void Main()
|
||||
{
|
||||
using (PdfDocument document = PdfDocument.Open(@"C:\temp\file.pdf"))
|
||||
{
|
||||
Console.WriteLine($"Document has {document.NumberOfPages} pages.");
|
||||
|
||||
if (document.TryGetForm(out AcroForm form))
|
||||
{
|
||||
foreach (AcroFieldBase field in form.GetFieldsForPage(1))
|
||||
{
|
||||
switch (field)
|
||||
{
|
||||
case AcroCheckboxField cb:
|
||||
if (cb.IsChecked)
|
||||
{
|
||||
Console.WriteLine($"Checkbox was checked: {cb.Information.MappingName}.");
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (document.TryGetXmpMetadata(out XmpMetadata metadata))
|
||||
{
|
||||
XDocument xmp = metadata.GetXDocument();
|
||||
}
|
||||
|
||||
if (document.TryGetBookmarks(out Bookmarks bookmarks))
|
||||
{
|
||||
Console.WriteLine($"Document contained bookmarks with {bookmarks.Roots.Count} root nodes.");
|
||||
}
|
||||
|
||||
Console.WriteLine($"Document uses version {document.Version} of the PDF specification.");
|
||||
|
||||
if (document.Advanced.TryGetEmbeddedFiles(out IReadOnlyList<EmbeddedFile> embeddedFiles))
|
||||
{
|
||||
Console.WriteLine($"Document contains {embeddedFiles.Count} embedded files.");
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
## Document Layout Analysis ##
|
||||
|
||||
PdfPig also comes with some tools for document layout analysis such as the Recursive XY Cut, Document Spectrum and Nearest Neighbour algorithms, along with others. It also provides support for exporting page contents to Alto, PageXML and hOcr format.
|
||||
|
||||
An example of the output of the Recursive XY Cut algorithm viewed in an external viewer such as [LayoutEvalGUI](https://www.primaresearch.org/tools/PerformanceEvaluation) is shown below:
|
||||
|
||||

|
||||
|
||||
See the [document layout analysis](https://github.com/UglyToad/PdfPig/wiki/Document-Layout-Analysis) page on the wiki for full details.
|
||||
|
||||
## Credit ##
|
||||
|
||||
This project wouldn't be possible without the work done by the [PDFBox](https://pdfbox.apache.org/) team and the Apache Foundation.
|
||||
|
||||
## Usage ##
|
||||
|
||||
The ```PdfDocument``` class provides access to the contents of a document loaded either from file or passed in as bytes. To open from a file use the ```PdfDocument.Open``` static method:
|
||||
|
||||
using UglyToad.PdfPig;
|
||||
using UglyToad.PdfPig.Content;
|
||||
|
||||
using (PdfDocument document = PdfDocument.Open(@"C:\my-file.pdf"))
|
||||
{
|
||||
int pageCount = document.NumberOfPages;
|
||||
|
||||
Page page = document.GetPage(1);
|
||||
|
||||
decimal widthInPoints = page.Width;
|
||||
decimal heightInPoints = page.Height;
|
||||
|
||||
string text = page.Text;
|
||||
}
|
||||
|
||||
```PdfDocument``` should only be used in a ```using``` statement since it implements ```IDisposable``` (unless the consumer disposes of it elsewhere).
|
||||
|
||||
Since this is alpha software the consumer should wrap all access in a ```try catch``` block since it is extremely likely to throw exceptions. As a fallback you can try running PDFBox using [IKVM](https://www.ikvm.net/) or using [PDFsharp](http://www.pdfsharp.net).
|
||||
|
||||
The document contains the version of the PDF specification it complies with, accessed by ```document.Version```:
|
||||
|
||||
decimal version = document.Version;
|
||||
|
||||
### Document Information ###
|
||||
|
||||
The ```PdfDocument``` provides access to the document metadata as ```DocumentInformation``` defined in the PDF file. These tend not to be provided therefore most of these entries will be ```null```:
|
||||
|
||||
PdfDocument document = PdfDocument.Open(fileName);
|
||||
|
||||
// The name of the program used to convert this document to PDF.
|
||||
string producer = document.Information.Producer;
|
||||
|
||||
// The title given to the document
|
||||
string title = document.Information.Title;
|
||||
// etc...
|
||||
|
||||
### Page ###
|
||||
|
||||
The ```Page``` contains the page width and height in points as well as mapping to the ```PageSize``` enum:
|
||||
|
||||
PageSize size = Page.Size;
|
||||
|
||||
bool isA4 = size == PageSize.A4;
|
||||
|
||||
```Page``` provides access to the text of the page:
|
||||
|
||||
string text = page.Text;
|
||||
|
||||
### Letter ###
|
||||
|
||||
Due to the way a PDF is structured internally the page text may not be a readable representation of the text as it appears in the document. Since PDF is a presentation format, text can be drawn in any order, not necessarily reading order. This means spaces may be missing or words may be in unexpected positions in the text.
|
||||
|
||||
To help users resolve actual text order on the page, the ```Page``` file provides access to a list of the letters:
|
||||
|
||||
|
||||
IReadOnlyList<Letter> letters = page.Letters;
|
||||
|
||||
These letters contain:
|
||||
|
||||
+ The text of the letter: ```letter.Value```.
|
||||
+ The location of the lower left of the letter: ```letter.Location```.
|
||||
+ The width of the letter: ```letter.Width```.
|
||||
+ The font size in unscaled relative text units (these sizes are internal to the PDF and do not correspond to sizes in pixels, points or other units): ```letter.FontSize```.
|
||||
+ The name of the font used to render the letter if available: ```letter.FontName```.
|
||||
|
||||
Letter position is measured in PDF coordinates where the origin is the lower left corner of the page. Therefore an higher Y value means closer to the top of the page.
|
||||
|
||||
At this stage letter position is experimental and **will change in future versions**! Do not rely on letter positions remaining constant between different versions of this package.
|
||||
|
||||
## Installation ##
|
||||
|
||||
The **pre-release** package is available via the releases tab or from Nuget:
|
||||
|
||||
[https://www.nuget.org/packages/PdfPig/](https://www.nuget.org/packages/PdfPig/)
|
||||
Reference in New Issue
Block a user