mirror of
https://github.com/UglyToad/PdfPig.git
synced 2025-10-08 00:14:35 +08:00
Update README.md
This commit is contained in:
44
README.md
44
README.md
@@ -10,8 +10,6 @@ containing text and geometrical shapes.
|
||||
|
||||
This project aims to port [PDFBox](https://github.com/apache/pdfbox) to C#.
|
||||
|
||||
**Migrating to 0.1.6 from 0.1.x?** Use this guide: [migration to 0.1.6](https://github.com/UglyToad/PdfPig/wiki/Migration-to-0.1.6).
|
||||
|
||||
## Wiki
|
||||
Check out our [wiki](https://github.com/UglyToad/PdfPig/wiki) for more examples and detailed guides on the API.
|
||||
|
||||
@@ -55,7 +53,7 @@ An example of the output of this is shown below:
|
||||
|
||||
Where for the PDF text ("Write something in") shown at the top the 3 words (in pink) are detected and each word contains the individual letters with glyph bounding boxes.
|
||||
|
||||
### Ceate PDF Document
|
||||
### Create PDF Document
|
||||
To create documents use the class `PdfDocumentBuilder`. The Standard 14 fonts provide a quick way to get started:
|
||||
|
||||
```cs
|
||||
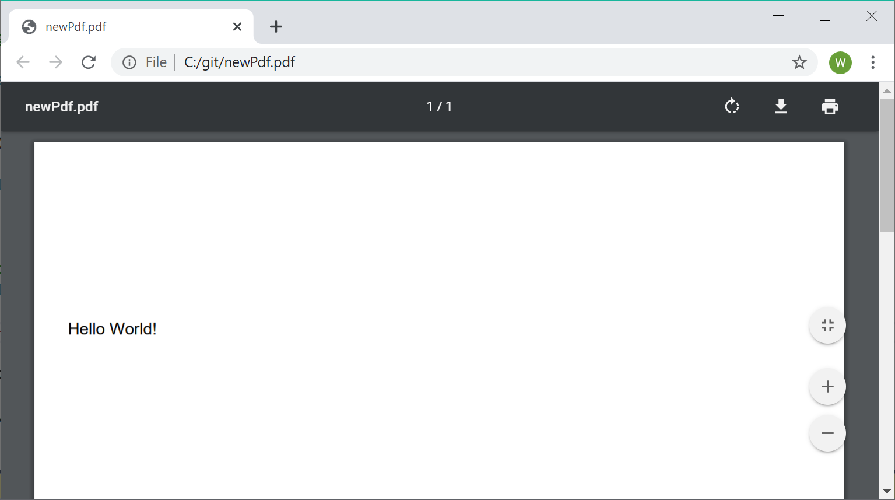
@@ -77,10 +75,10 @@ The output is a 1 page PDF document with the text "Hello World!" in Helvetica ne
|
||||
|
||||
|
||||
|
||||
Each font must be registered with the PdfDocumentBuilder prior to use enable pages to share the font resources. Only Standard 14 fonts and TrueType fonts (.ttf) are supported.
|
||||
Each font must be registered with the `PdfDocumentBuilder` prior to use enable pages to share the font resources. Only Standard 14 fonts and TrueType fonts (.ttf) are supported.
|
||||
|
||||
### Advanced Document Extraction
|
||||
In this example a more advanced document extraction is performed. PdfDocumentBuilder is used to create a copy of the pdf with debug information (bounding boxes and reading order) added.
|
||||
In this example a more advanced document extraction is performed. `PdfDocumentBuilder` is used to create a copy of the pdf with debug information (bounding boxes and reading order) added.
|
||||
|
||||
|
||||
```cs
|
||||
@@ -183,7 +181,7 @@ The document contains the version of the PDF specification it complies with, acc
|
||||
|
||||
decimal version = document.Version;
|
||||
|
||||
### Document Creation (0.0.5)
|
||||
### Document Creation
|
||||
|
||||
The `PdfDocumentBuilder` creates a new document with no pages or content.
|
||||
|
||||
@@ -256,7 +254,7 @@ string title = document.Information.Title;
|
||||
// etc...
|
||||
```
|
||||
|
||||
### Document Structure (0.0.3)
|
||||
### Document Structure
|
||||
|
||||
The document now has a Structure member:
|
||||
|
||||
@@ -286,21 +284,21 @@ bool isA4 = size == PageSize.A4;
|
||||
|
||||
string text = page.Text;
|
||||
|
||||
There is a new (0.0.3) method which provides access to the words. This uses basic heuristics and is not reliable or well-tested:
|
||||
There is a method which provides access to the words. The default method uses basic heuristics. For advanced cases, You can also implement your own `IWordExtractor` or use the `NearestNeighbourWordExtractor`:
|
||||
|
||||
IEnumerable<Word> words = page.GetWords();
|
||||
|
||||
You can also (0.0.6) access the raw operations used in the page's content stream for drawing graphics and content on the page:
|
||||
You can also access the raw operations used in the page's content stream for drawing graphics and content on the page:
|
||||
|
||||
IReadOnlyList<IGraphicsStateOperation> operations = page.Operations;
|
||||
|
||||
Consult the PDF specification for the meaning of individual operators.
|
||||
|
||||
There is also an early access (0.0.3) API for retrieving the raw bytes of PDF image objects per page:
|
||||
There is also an API for retrieving the PDF image objects per page:
|
||||
|
||||
IEnumerable<XObjectImage> images = page.ExperimentalAccess.GetRawImages();
|
||||
IEnumerable<XObjectImage> images = page.GetImages();
|
||||
|
||||
This API will be changed in future releases.
|
||||
Please read the [wiki on Images](https://github.com/UglyToad/PdfPig/wiki/Images).
|
||||
|
||||
### Letter
|
||||
|
||||
@@ -322,15 +320,15 @@ These letters contain:
|
||||
|
||||
Letter position is measured in PDF coordinates where the origin is the lower left corner of the page. Therefore a higher Y value means closer to the top of the page.
|
||||
|
||||
### Annotations (0.0.5)
|
||||
### Annotations
|
||||
|
||||
Early support for retrieving annotations on each page is provided using the method:
|
||||
Retrieving annotations on each page is provided using the method:
|
||||
|
||||
page.ExperimentalAccess.GetAnnotations()
|
||||
page.GetAnnotations()
|
||||
|
||||
This call is not cached and the document must not have been disposed prior to use. The annotations API may change in future.
|
||||
This call is not cached and the document must not have been disposed prior to use.
|
||||
|
||||
### Bookmarks (0.0.10)
|
||||
### Bookmarks
|
||||
|
||||
The bookmarks (outlines) of a document may be retrieved at the document level:
|
||||
|
||||
@@ -338,7 +336,7 @@ The bookmarks (outlines) of a document may be retrieved at the document level:
|
||||
|
||||
This will return `false` if the document does not define any bookmarks.
|
||||
|
||||
### Forms (0.0.10)
|
||||
### Forms
|
||||
|
||||
Form fields for interactive forms (AcroForms) can be retrieved using:
|
||||
|
||||
@@ -350,15 +348,15 @@ The fields can be accessed using the `AcroForm`'s `Fields` property. Since the f
|
||||
|
||||
Please note the forms are readonly and values cannot be changed or added using PdfPig.
|
||||
|
||||
### Hyperlinks (0.1.0)
|
||||
### Hyperlinks
|
||||
|
||||
A page has a method to extract hyperlinks (annotations of link type):
|
||||
|
||||
IReadOnlyList<UglyToad.PdfPig.Content.Hyperlink> hyperlinks = page.GetHyperlinks();
|
||||
|
||||
### TrueType (0.1.0)
|
||||
### TrueType
|
||||
|
||||
The classes used to work with TrueType fonts in the PDF file are now available for public consumption. Given an input file:
|
||||
The classes used to work with TrueType fonts in the PDF file are available for public consumption. Given an input file:
|
||||
|
||||
|
||||
```cs
|
||||
@@ -372,7 +370,7 @@ TrueTypeFont font = TrueTypeFontParser.Parse(input);
|
||||
|
||||
The parsed font can then be inspected.
|
||||
|
||||
### Embedded Files (0.1.0)
|
||||
### Embedded Files
|
||||
|
||||
PDF files may contain other files entirely embedded inside them for document annotations. The list of embedded files and their byte content may be accessed:
|
||||
|
||||
@@ -386,7 +384,7 @@ if (document.Advanced.TryGetEmbeddedFiles(out IReadOnlyList<EmbeddedFile> files)
|
||||
}
|
||||
```
|
||||
|
||||
### Merging (0.1.2)
|
||||
### Merging
|
||||
|
||||
You can merge 2 or more existing PDF files using the `PdfMerger` class:
|
||||
|
||||
|
||||
Reference in New Issue
Block a user