mirror of
https://github.com/UglyToad/PdfPig.git
synced 2026-03-10 00:23:29 +08:00
merge master
This commit is contained in:
29
README.md
29
README.md
@@ -43,6 +43,12 @@ The simplest usage at this stage is to open a document, reading the words from e
|
||||
}
|
||||
}
|
||||
|
||||
An example of the output of this is shown below:
|
||||
|
||||

|
||||
|
||||
Where for the PDF text ("Write something in") shown at the top the 3 words (in pink) are detected and each word contains the individual letters with glyph bounding boxes.
|
||||
|
||||
To create documents use the class ```PdfDocumentBuilder```. The Standard 14 fonts provide a quick way to get started:
|
||||
|
||||
PdfDocumentBuilder builder = new PdfDocumentBuilder();
|
||||
@@ -52,12 +58,17 @@ To create documents use the class ```PdfDocumentBuilder```. The Standard 14 font
|
||||
// Fonts must be registered with the document builder prior to use to prevent duplication.
|
||||
PdfDocumentBuilder.AddedFont font = builder.AddStandard14Font(Standard14Font.Helvetica);
|
||||
|
||||
page.AddText("Hello World!", 12, new PdfPoint(25, 520), font);
|
||||
page.AddText("Hello World!", 12, new PdfPoint(25, 700), font);
|
||||
|
||||
byte[] documentBytes = builder.Build();
|
||||
|
||||
File.WriteAllBytes(@"C:\git\newPdf.pdf", documentBytes);
|
||||
|
||||
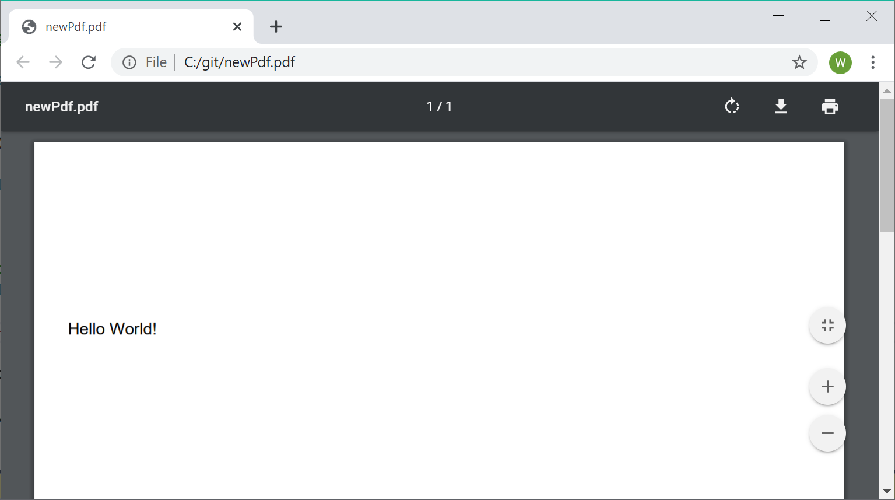
The output is a 1 page PDF document with the text "Hello World!" in Helvetica near the top of the page:
|
||||
|
||||
|
||||
|
||||
|
||||
Each font must be registered with the PdfDocumentBuilder prior to use enable pages to share the font resources. Only Standard 14 fonts and TrueType fonts (.ttf) are supported.
|
||||
|
||||
## Usage ##
|
||||
@@ -270,9 +281,19 @@ The classes used to work with TrueType fonts in the PDF file are now available f
|
||||
|
||||
The parsed font can then be inspected.
|
||||
|
||||
## Issues ##
|
||||
### Embedded Files (0.1.0) ###
|
||||
|
||||
At this stage the software is in Alpha. In order to proceed to Beta and production we need to see a wide variety of document types.
|
||||
PDF files may contain other files entirely embedded inside them for document annotations. The list of embedded files and their byte content may be accessed:
|
||||
|
||||
if (document.Advanced.TryGetEmbeddedFiles(out IReadOnlyList<EmbeddedFile> files)
|
||||
&& files.Count > 0)
|
||||
{
|
||||
var firstFile = files[0];
|
||||
string name = firstFile.Name;
|
||||
IReadOnlyList<byte> bytes = firstFile.Bytes;
|
||||
}
|
||||
|
||||
## Issues ##
|
||||
|
||||
Please do file an issue if you encounter a bug.
|
||||
|
||||
@@ -282,8 +303,6 @@ However in order for us to assist you, you **must** provide the file which cause
|
||||
|
||||
*Why is class or property X internal?* Internal properties and classes are not stable enough for the end user yet. If you want to access them feel free to use reflection but be aware they may change or disappear between versions.
|
||||
|
||||
Most testing has taken place with Latin character sets. Due to the more complex way the PDF specification handles CJK (Chinese, Japanese and Korean) character sets these will probably not be handled correctly for now. Please raise an issue (or preferably a pull request) if you have problems trying to read these documents.
|
||||
|
||||
## Credit ##
|
||||
|
||||
This project wouldn't be possible without the work done by the [PDFBox](https://pdfbox.apache.org/) team and the Apache Foundation. Any bugs in the code are entirely my fault.
|
||||
|
||||
BIN
documentation/Letters/example-text-extraction.png
Normal file
BIN
documentation/Letters/example-text-extraction.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 22 KiB |
BIN
documentation/builder-output.png
Normal file
BIN
documentation/builder-output.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 17 KiB |
@@ -902,6 +902,10 @@ namespace UglyToad.PdfPig.Fonts.CompactFontFormat.CharStrings
|
||||
{
|
||||
precedingNumbers = 0;
|
||||
}
|
||||
else if (identifier.IsMultiByteCommand && identifier.CommandId > 35)
|
||||
{
|
||||
precedingNumbers = 0;
|
||||
}
|
||||
else
|
||||
{
|
||||
stemCount += SafeStemCount(precedingNumbers);
|
||||
|
||||
@@ -27,7 +27,7 @@
|
||||
var content = File.ReadAllText(path);
|
||||
var input = StringBytesTestConverter.Convert(content, false);
|
||||
|
||||
var result = parser.Parse(input.Bytes);
|
||||
var result = parser.Parse(1, input.Bytes);
|
||||
|
||||
Assert.NotEmpty(result);
|
||||
}
|
||||
@@ -39,7 +39,7 @@
|
||||
var content = File.ReadAllText(path);
|
||||
var input = StringBytesTestConverter.Convert(content, false);
|
||||
|
||||
var result = parser.Parse(input.Bytes);
|
||||
var result = parser.Parse(1, input.Bytes);
|
||||
|
||||
var replacementRegex = new Regex(@"\s(\.\d+)\b");
|
||||
|
||||
@@ -72,7 +72,7 @@
|
||||
ET";
|
||||
var input = StringBytesTestConverter.Convert(s, false);
|
||||
|
||||
var result = parser.Parse(input.Bytes);
|
||||
var result = parser.Parse(1, input.Bytes);
|
||||
|
||||
using (var stream = new MemoryStream())
|
||||
{
|
||||
@@ -102,7 +102,7 @@ ET";
|
||||
ET";
|
||||
var input = StringBytesTestConverter.Convert(s, false);
|
||||
|
||||
var result = parser.Parse(input.Bytes);
|
||||
var result = parser.Parse(1, input.Bytes);
|
||||
|
||||
Assert.Equal(7, result.Count);
|
||||
|
||||
@@ -138,7 +138,7 @@ ET";
|
||||
|
||||
var input = StringBytesTestConverter.Convert(s, false);
|
||||
|
||||
var result = parser.Parse(input.Bytes);
|
||||
var result = parser.Parse(1, input.Bytes);
|
||||
|
||||
Assert.Equal(4, result.Count);
|
||||
|
||||
@@ -163,7 +163,7 @@ cm BT 0.0001 Tc 19 0 0 19 0 0 Tm /Tc1 1 Tf ( \(sleep 1; printf ""QUIT\\r\\n""\
|
||||
|
||||
var input = StringBytesTestConverter.Convert(s, false);
|
||||
|
||||
var result = parser.Parse(input.Bytes);
|
||||
var result = parser.Parse(1, input.Bytes);
|
||||
|
||||
Assert.Equal(9, result.Count);
|
||||
|
||||
|
||||
@@ -53,7 +53,8 @@
|
||||
private IFont activeExtendedGraphicsStateFont;
|
||||
private InlineImageBuilder inlineImageBuilder;
|
||||
private bool currentPathAdded;
|
||||
|
||||
private int pageNumber;
|
||||
|
||||
/// <summary>
|
||||
/// A counter to track individual calls to <see cref="ShowText"/> operations used to determine if letters are likely to be
|
||||
/// in the same word/group. This exposes internal grouping of letters used by the PDF creator which may correspond to the
|
||||
@@ -98,8 +99,9 @@
|
||||
ColorSpaceContext = new ColorSpaceContext(GetCurrentState, resourceStore);
|
||||
}
|
||||
|
||||
public PageContent Process(IReadOnlyList<IGraphicsStateOperation> operations)
|
||||
public PageContent Process(int pageNumberCurrent, IReadOnlyList<IGraphicsStateOperation> operations)
|
||||
{
|
||||
pageNumber = pageNumberCurrent;
|
||||
CloneAllStates();
|
||||
|
||||
ProcessOperations(operations);
|
||||
@@ -375,7 +377,7 @@
|
||||
|
||||
var contentStream = formStream.Decode(filterProvider);
|
||||
|
||||
var operations = pageContentParser.Parse(new ByteArrayInputBytes(contentStream));
|
||||
var operations = pageContentParser.Parse(pageNumber, new ByteArrayInputBytes(contentStream));
|
||||
|
||||
// 3. We don't respect clipping currently.
|
||||
|
||||
|
||||
@@ -6,7 +6,6 @@
|
||||
using Colors;
|
||||
using Content;
|
||||
using Core;
|
||||
using Exceptions;
|
||||
using Filters;
|
||||
using PdfPig.Core;
|
||||
using Tokenization.Scanner;
|
||||
|
||||
@@ -6,6 +6,6 @@
|
||||
|
||||
internal interface IPageContentParser
|
||||
{
|
||||
IReadOnlyList<IGraphicsStateOperation> Parse(IInputBytes inputBytes);
|
||||
IReadOnlyList<IGraphicsStateOperation> Parse(int pageNumber, IInputBytes inputBytes);
|
||||
}
|
||||
}
|
||||
@@ -1,6 +1,8 @@
|
||||
namespace UglyToad.PdfPig.Parser
|
||||
{
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.Linq;
|
||||
using Core;
|
||||
using Graphics;
|
||||
using Graphics.Operations;
|
||||
@@ -17,13 +19,15 @@
|
||||
this.operationFactory = operationFactory;
|
||||
}
|
||||
|
||||
public IReadOnlyList<IGraphicsStateOperation> Parse(IInputBytes inputBytes)
|
||||
public IReadOnlyList<IGraphicsStateOperation> Parse(int pageNumber, IInputBytes inputBytes)
|
||||
{
|
||||
var scanner = new CoreTokenScanner(inputBytes);
|
||||
|
||||
var precedingTokens = new List<IToken>();
|
||||
var graphicsStateOperations = new List<IGraphicsStateOperation>();
|
||||
|
||||
var lastEndImageOffset = new long?();
|
||||
|
||||
while (scanner.MoveNext())
|
||||
{
|
||||
var token = scanner.CurrentToken;
|
||||
@@ -47,15 +51,62 @@
|
||||
|
||||
graphicsStateOperations.Add(new BeginInlineImageData(dictionary));
|
||||
graphicsStateOperations.Add(new EndInlineImage(inlineImageData.Data));
|
||||
|
||||
lastEndImageOffset = scanner.CurrentPosition - 2;
|
||||
|
||||
precedingTokens.Clear();
|
||||
}
|
||||
else if (token is OperatorToken op)
|
||||
{
|
||||
var operation = operationFactory.Create(op, precedingTokens);
|
||||
|
||||
if (operation != null)
|
||||
// Handle an end image where the stream of image data contained EI but was not actually a real end image operator.
|
||||
if (op.Data == "EI")
|
||||
{
|
||||
graphicsStateOperations.Add(operation);
|
||||
// Check an end image operation was the last thing that happened.
|
||||
IGraphicsStateOperation lastOperation = graphicsStateOperations.Count > 0
|
||||
? graphicsStateOperations[graphicsStateOperations.Count - 1]
|
||||
: null;
|
||||
|
||||
if (lastEndImageOffset == null || lastOperation == null || !(lastOperation is EndInlineImage lastEndImage))
|
||||
{
|
||||
throw new PdfDocumentFormatException("Encountered End Image token outside an inline image on " +
|
||||
$"page {pageNumber} at offset in content: {scanner.CurrentPosition}.");
|
||||
}
|
||||
|
||||
// Work out how much data we missed between the false EI operator and the actual one.
|
||||
var actualEndImageOffset = scanner.CurrentPosition - 3;
|
||||
|
||||
var gap = (int)(actualEndImageOffset - lastEndImageOffset);
|
||||
|
||||
var from = inputBytes.CurrentOffset;
|
||||
inputBytes.Seek(lastEndImageOffset.Value);
|
||||
|
||||
// Recover the full image data.
|
||||
{
|
||||
var missingData = new byte[gap];
|
||||
var read = inputBytes.Read(missingData);
|
||||
if (read != gap)
|
||||
{
|
||||
throw new InvalidOperationException($"Failed to read expected buffer length {gap} on page {pageNumber} " +
|
||||
$"when reading inline image at offset in content: {lastEndImageOffset.Value}.");
|
||||
}
|
||||
|
||||
// Replace the last end image operator with one containing the full set of data.
|
||||
graphicsStateOperations.Remove(lastEndImage);
|
||||
graphicsStateOperations.Add(new EndInlineImage(lastEndImage.ImageData.Concat(missingData).ToArray()));
|
||||
}
|
||||
|
||||
lastEndImageOffset = actualEndImageOffset;
|
||||
|
||||
inputBytes.Seek(from);
|
||||
}
|
||||
else
|
||||
{
|
||||
var operation = operationFactory.Create(op, precedingTokens);
|
||||
|
||||
if (operation != null)
|
||||
{
|
||||
graphicsStateOperations.Add(operation);
|
||||
}
|
||||
}
|
||||
|
||||
precedingTokens.Clear();
|
||||
|
||||
@@ -54,8 +54,8 @@
|
||||
rotation = new PageRotationDegrees(rotateToken.Int);
|
||||
}
|
||||
|
||||
MediaBox mediaBox = GetMediaBox(number, dictionary, pageTreeMembers, isLenientParsing);
|
||||
CropBox cropBox = GetCropBox(dictionary, pageTreeMembers, mediaBox, isLenientParsing);
|
||||
MediaBox mediaBox = GetMediaBox(number, dictionary, pageTreeMembers);
|
||||
CropBox cropBox = GetCropBox(dictionary, pageTreeMembers, mediaBox);
|
||||
|
||||
var stackDepth = 0;
|
||||
|
||||
@@ -109,7 +109,7 @@
|
||||
}
|
||||
}
|
||||
|
||||
content = GetContent(bytes, cropBox, userSpaceUnit, rotation, isLenientParsing);
|
||||
content = GetContent(number, bytes, cropBox, userSpaceUnit, rotation, isLenientParsing);
|
||||
}
|
||||
else
|
||||
{
|
||||
@@ -122,7 +122,7 @@
|
||||
|
||||
var bytes = contentStream.Decode(filterProvider);
|
||||
|
||||
content = GetContent(bytes, cropBox, userSpaceUnit, rotation, isLenientParsing);
|
||||
content = GetContent(number, bytes, cropBox, userSpaceUnit, rotation, isLenientParsing);
|
||||
}
|
||||
|
||||
var page = new Page(number, dictionary, mediaBox, cropBox, rotation, content,
|
||||
@@ -137,16 +137,18 @@
|
||||
return page;
|
||||
}
|
||||
|
||||
private PageContent GetContent(IReadOnlyList<byte> contentBytes, CropBox cropBox, UserSpaceUnit userSpaceUnit, PageRotationDegrees rotation, bool isLenientParsing)
|
||||
private PageContent GetContent(int pageNumber, IReadOnlyList<byte> contentBytes, CropBox cropBox, UserSpaceUnit userSpaceUnit,
|
||||
PageRotationDegrees rotation,
|
||||
bool isLenientParsing)
|
||||
{
|
||||
var operations = pageContentParser.Parse(new ByteArrayInputBytes(contentBytes));
|
||||
var operations = pageContentParser.Parse(pageNumber, new ByteArrayInputBytes(contentBytes));
|
||||
|
||||
var context = new ContentStreamProcessor(cropBox.Bounds, resourceStore, userSpaceUnit, rotation, isLenientParsing, pdfScanner,
|
||||
pageContentParser,
|
||||
filterProvider,
|
||||
log);
|
||||
|
||||
return context.Process(operations);
|
||||
return context.Process(pageNumber, operations);
|
||||
}
|
||||
|
||||
private static UserSpaceUnit GetUserSpaceUnits(DictionaryToken dictionary)
|
||||
@@ -160,15 +162,15 @@
|
||||
return spaceUnits;
|
||||
}
|
||||
|
||||
private CropBox GetCropBox(DictionaryToken dictionary, PageTreeMembers pageTreeMembers, MediaBox mediaBox, bool isLenientParsing)
|
||||
private CropBox GetCropBox(DictionaryToken dictionary, PageTreeMembers pageTreeMembers, MediaBox mediaBox)
|
||||
{
|
||||
CropBox cropBox;
|
||||
if (dictionary.TryGet(NameToken.CropBox, out var cropBoxObject) &&
|
||||
DirectObjectFinder.TryGet(cropBoxObject, pdfScanner, out ArrayToken cropBoxArray))
|
||||
{
|
||||
if (cropBoxArray.Length != 4 && isLenientParsing)
|
||||
if (cropBoxArray.Length != 4)
|
||||
{
|
||||
log.Error($"The CropBox was the wrong length in the dictionary: {dictionary}. Array was: {cropBoxArray}.");
|
||||
log.Error($"The CropBox was the wrong length in the dictionary: {dictionary}. Array was: {cropBoxArray}. Using MediaBox.");
|
||||
|
||||
cropBox = new CropBox(mediaBox.Bounds);
|
||||
|
||||
@@ -185,17 +187,17 @@
|
||||
return cropBox;
|
||||
}
|
||||
|
||||
private MediaBox GetMediaBox(int number, DictionaryToken dictionary, PageTreeMembers pageTreeMembers, bool isLenientParsing)
|
||||
private MediaBox GetMediaBox(int number, DictionaryToken dictionary, PageTreeMembers pageTreeMembers)
|
||||
{
|
||||
MediaBox mediaBox;
|
||||
if (dictionary.TryGet(NameToken.MediaBox, out var mediaboxObject)
|
||||
&& DirectObjectFinder.TryGet(mediaboxObject, pdfScanner, out ArrayToken mediaboxArray))
|
||||
{
|
||||
if (mediaboxArray.Length != 4 && isLenientParsing)
|
||||
if (mediaboxArray.Length != 4)
|
||||
{
|
||||
log.Error($"The MediaBox was the wrong length in the dictionary: {dictionary}. Array was: {mediaboxArray}.");
|
||||
log.Error($"The MediaBox was the wrong length in the dictionary: {dictionary}. Array was: {mediaboxArray}. Defaulting to US Letter.");
|
||||
|
||||
mediaBox = MediaBox.A4;
|
||||
mediaBox = MediaBox.Letter;
|
||||
|
||||
return mediaBox;
|
||||
}
|
||||
@@ -208,14 +210,10 @@
|
||||
|
||||
if (mediaBox == null)
|
||||
{
|
||||
if (isLenientParsing)
|
||||
{
|
||||
mediaBox = MediaBox.A4;
|
||||
}
|
||||
else
|
||||
{
|
||||
throw new InvalidOperationException("No mediabox was present for page: " + number);
|
||||
}
|
||||
log.Error($"The MediaBox was the wrong missing for page {number}. Using US Letter.");
|
||||
|
||||
// PDFBox defaults to US Letter.
|
||||
mediaBox = MediaBox.Letter;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@@ -12,7 +12,7 @@
|
||||
<PackageTags>PDF;Reader;Document;Adobe;PDFBox;PdfPig;pdf-extract</PackageTags>
|
||||
<RepositoryUrl>https://github.com/UglyToad/PdfPig</RepositoryUrl>
|
||||
<GenerateDocumentationFile>true</GenerateDocumentationFile>
|
||||
<Version>0.1.0-beta001</Version>
|
||||
<Version>0.1.0-beta002</Version>
|
||||
<AssemblyVersion>0.1.0.0</AssemblyVersion>
|
||||
<FileVersion>0.1.0.0</FileVersion>
|
||||
<PackageIconUrl>https://raw.githubusercontent.com/UglyToad/PdfPig/master/documentation/pdfpig.png</PackageIconUrl>
|
||||
|
||||
Reference in New Issue
Block a user